مفهوم Aggregation Pipeline در MongoDB
سه شنبه 18 آبان 1395در این مقاله ، می آموزیم که چطور می توانیم در پایگاه داده ی MongoDB ،یک Aggregation Pipeline داشته باشیم. (خط لوله های متراکم) . همچنین مزایا ی این نوع Pipeline را نیز برای شما بیان خواهیم کرد.

مقدمه
عملیات Aggregration در همه ی پایگاه داده ها مهم و حائز اهمیت هستند. برای انجام عملیات Aggregation ، پایگاه داده ی Mongo DB مقادیر را از اسناد مختلف جمع می کند ، در یک مکان گردآوردی می کند و سپس عملیات مختلفی را بر روی آن ها انجام میدهد و در نهایت، یک مقدار به شما برمی گرداند. SQL از توابع Aggregration برای برگرداندن یک مقدار که از محاسبه چندین مقدار مختلف ذخیره شده در ستون ها به دست می آید، استفاده می کند.
MongoDB از سه راه برای انجام Aggregration استفاده می کند: aggregation pipeline ، map-reduce function و متدهای single purpose aggregation.
در این مقاله، ما بر روی روش aggregation pipeline تمرکز می کنیم و تلاش می کنیم با استفاده از مثال های مختلف، بخش های مهم این روش را پوشش بدهیم.
Aggregation Pipeline
فریم ورک Aggregration مربوط به MongoDB بر اساس مفهوم data processing pipeline طراحی شده است. Aggregation pipeline مشابه UNIX world pipeline است. در مراحل اولیه یک collection داریم . این collection از طریق اسناد (document) ارسال می شود. این اسناد در طول خط لوله ها انتقال پیدا می کنند و در قالب stage هایی قرار می گیرند تا در نهایت، ما بتوانیم از آن ها یک نتیجه واحد بگیریم .
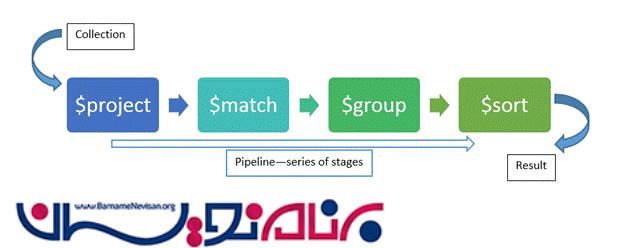
در این شکل می بینید که collection از stage های مختلفی عبور می کند که برخی از آن ها عبارتند از: $project, $match, $group, $sort. هر کدام از این stage ها می توانند چندین بار تکرار شوند.
stage های مختلف در pipeline (خط لوله) عبارتند از:
$project ، داده ها را انتخاب و فرم دهی می کند.
$match ، داده ها را فیلتر می کند.
$group داده ها را aggregrate می کند.
$sort داده ها را مرتب می کند.
$skipداده ها را skip می کند.
$limit داده ها را محدود می کند.
$unwind داده ها را نرمال سازی می کند.
بیایید مفهوم aggregration را برای شما با یک مثال، شفاف سازی کنیم. نگران syntax دستور زیر نباشید، در ادامه آن را هم مورد بررسی قرار خواهیم داد.
db.mycollection.aggregate([{
$match: {
'phone_type': 'smart'
}
}, {
$group: {
'_id': '$brand_name',
total: {
$sum: '$price'
}
}
}])

همان طور که در دیاگرام می توانید ببینید، ما یک مجموعه داریم. مرحله $match داده ها را فیلتر می کند. سپس در مرحله بعدی pipeline ، اسناد گروه بندی می شوند تا در نهایت بتوانیم جواب نهایی را از آن ها بگیریم.
آماده سازی داده های آزمایشی
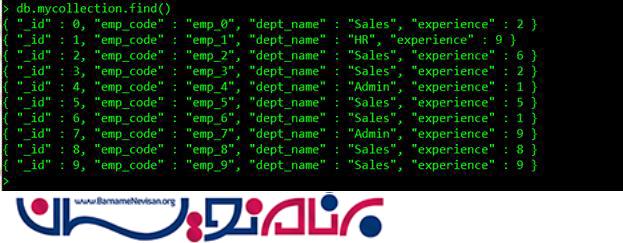
برای اجرای دستورات Mongo Shell ، ما نیاز به یک پایگاه داده و تعدادی داده آزمایشی داریم. بنابراین ابتدا بیایید پایگاه داده و مجموعه داده هایمان را ایجاد کنیم.
Use mydb; // database name
dept = ['IT', 'Sales', 'HR', 'Admin'];
for (i = 0; i < 10; i++) {
db.mycollection.insert({ //mycollection is collection name
'_id': i,
'emp_code': 'emp_' + i,
'dept_name': dept[Math.round(Math.random() * 3)],
'experience': Math.round(Math.random() * 10),
});
دستور زیر تعدادی داده آزمایشی در یک مجموعه به نام mycollection در پایگاه داده ای به نام mydb می ریزد.
db.mycollection.aggregate([{ $match: { 'phone_type': 'smart' } }, { $group: { '_id': '$brand_name', total: { $sum: '$price' } } }])
syntax این دستورات ، بسیار ساده است. تابع aggregrate آرایه ای از argument ها را می گیرد. در آرایه، ما می توانیم stage های مختلفی از Pipeline را پاس بدهیم.
در مثال بالا، دو فاز مختلف از pipeline را انتقال داده ایم که یکی از آن ها $match است که داده های ما را فیلتر می کند و دیگری $group است که داده ها را گروه بندی می کند و مجوعه رکورد نهایی ما را آماده می کند.
stage های یک خط لوله (pipeline)
1- $project
در فاز $project، ما می توانیم یک کلید اضافه کنیم، یک کلید حذف کنیم، یک کلید را باز سازی کنیم. همچنین توابع ساده ای نیز وجود دارند که ما می توانیم بر روی کلیدهایمان پیاده سازی کنیم:$toUpper, $toLower, $add, $multiply و غیره...
بیایید از $project برای شکل دهی ساختار اسنادی که قبلا ساخته ایم، استفاده کنیم.
db.mycollection.aggregate([{
$project: {
_id: 0,
'department': {
$toUpper: '$dept_name'
},
'new_experience': {
$add: ['$experience', 1]
}
}
}])
در aggregrate query ما در حال پردازش اسناد هستیم. نکته ای که در اینجا باید مورد توجه قرار بگیرد این است که فیلد ‘dept_name’ با پیشوند $ مقدار دهی می شود تا به این وسیله Mongo Shell بفهمد که این فیلد، نام اصلی سند است. فیلد جدید دیگر ، new_experience است که با استفاده از تابع $add function ایجاد شده است.
خروجی ما به صورت زیر خواهد بود:
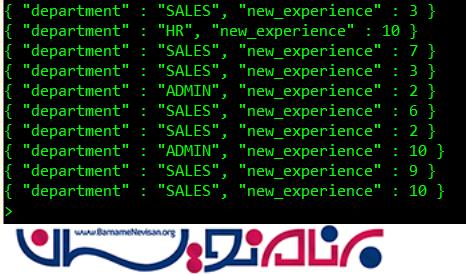
2-$match
این مورد دقیقا مشابه عبارت "Where" در Sql عمل می کند تا داده ها را بتواند فیلتر کند. دلیل این که ما بخواهیم اسناد را مورد فیلتر قرار بدهیم این است که گاهی اوقات ممکن است اعمال خاصی را فقط بر روی بخش خاصی از داده ها انجام بدهیم.
db.mycollection.aggregate([{
$match: {
dept_name: 'Sales'
}
}])

3- $group
همان طور که از نام آن پیداست، اسناد را بر اساس کلید ها گروه بندی می کند. مثلا می توانیم کارمندان را بر اساس نام بخشی که در آن مشغول به کار هستند، دسته بندی کنیم و تعداد کارکنان هر بخش را بیابیم.
db.mycollection.aggregate([{
$group: {
_id: '$dept_name',
no_of_employees: {
$sum: 1
}
}
}])
در اینجا ، _id عاملی است که گروه بندی بر اساس آن انجام می شود و ما یک کلید دیگر به نام no_of_employees تعریف کرده ایم و همچنین از $sum استفاده کرده ایم تا تعداد کل داده ها در هر گروه را پیدا کنیم.

بیایید خروجی را کمی بهتر به کاربر نمایش بدهیم
$group: {
_id: {
'department': '$dept_name'
},
no_of_employees: {
$sum: 1
}
}
}])
بیایید حالا اسناد را بر اساس بیشتر از یک کلید مرتب کنیم. تنها کاری که باید انجام بدهیم این است که کلیدها را در فیلد _id تعریف کنیم.
db.mycollection.aggregate([{
$group: {
_id: {
'department': '$dept_name',
'year_of_experience': '$experience'
},
no_of_employees: {
$sum: 1
}
}
}])
 4- $sort
4- $sort
این مورد به شما کمک می کند تا داده ها را بعد از aggregation به صورت صعودی یا نزولی مرتب کنید. بیایید نام بخش ها را بر اساس صعودی مرتب کنیم و تعداد کارکنان هر بخش را پیدا کنیم.
db.mycollection.aggregate([{
$group: {
_id: '$dept_name',
no_of_employees: {
$sum: 1
}
}
}, {
$sort: {
_id: 1
}
}])
5- $skip and $limit
$skip and $limit برای مواردی به کار می روند که ما بخواهیم موارد خاصی را پیدا کنیم. برای استفاده از این موارد، ابتدا باید داده ها را مرتب کنیم. در غیر اینصورت، نتیجه ای که دریافت می کنیم، درست نخواهد بود.
ما ابتدا داده ها را skip و سپس آن ها را limit می کنیم.
db.mycollection.aggregate([{
$group: {
_id: '$dept_name',
no_of_employees: {
$sum: 1
}
}
}, {
$sort: {
_id: 1
}
}, {
$skip: 2
}, {
$limit: 1
}])
اسناد گروه بندی می شوند، سپس مرتب می شوند، سپس ما از دو تا سند عبور می کنیم (skip ) . سپس فقط یکی از آن ها را با limit برمی گردانیم.
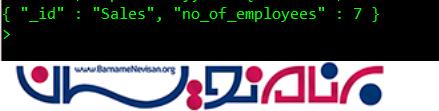
6-$first and $last
با استفاده از این دو مورد، ما می توانیم به اولین سند و آخرین سند در حال پردازش در pipeline دسترسی پیدا کنیم.
db.mycollection.aggregate([{
$group: {
_id: '$dept_name',
no_of_employees: {
$sum: 1
},
first_record: {
$first: '$emp_code'
}
}
}])

7-$unwind
همان طور که می دانیم ، اسناد در Mongo DB به صورت آرایه هستند. اگر بخواهیم بر اساس یک مورد در داخل گروه، اسناد را گروه بندی کنیم، کار آسانی نیست. $unwind ابتدا حالت اتصال داده ها به هم را برمیدارد و سپس داده ها را بر اساسی به هم متصل می کند که بتوانیم گروه بندی مورد نظرمان را نیز انجام بدهیم.
فرض کنید یک سند مطابق زیر داریم:
{
a: somedata,
b: someotherdata,
c: [arr1, arr2, arr3]
}
After $unwind on‘ c’, we will get three documents.
{
a: somedata,
b: someotherdata,
c: arr1
} {
a: somedata,
b: someotherdata,
c: arr2
} {
a: somedata,
b: someotherdata,
c: arr3
}
8-عبارات Aggregation
بیایید به تعدادی عبارت نگاهی بندازیم که در sql بسیار معروف و پرکاربرد هستند و معادل آن ها در MongoDB را معرفی کنیم.
1-$Sum که آن را در یک مثال در بالا بررسی کردیم.
2-$avg میانگین داده ها را برمی گرداند، و دقیقا مشابه sum است.
3-$min داده ی min یا حداقل را پیدا می کند (در بین داده های گروه بندی شده)
4-$max داده ی max یا حداکثر را پیدا می کند. (در بین داده های گروه بندی شده)

- SQL Server
- 5k بازدید
- 1 تشکر