collation در SQL
دوشنبه 18 آبان 1394در این مقاله مفهوم Collation و مفاهیم مرتبط با آن به صورت مفصل توضیح داده خواهد شد.Collation در واقع روش مرتب سازی و مقایسه اطلاعات (نه مقایسه خیلی پیچیده بلکه مقایسه در حد حروف کوچک و بزرگ) است .

Collation چیست ؟
روش مرتب سازی و مقایسه اطلاعات (نه مقایسه خیلی پیچیده بلکه مقایسه در حد حروف کوچک و بزرگ) را Collation می گویند.این مفهوم فقط برای داده های کاراکتری معنا دارد . Collation سطوح مختلفی دارد از جمله تعریف Collation در سطوح
1 – Instance
2- Data Base
3- Table
در سطح Instance شما در هنگام نصب SQL می توانید Collation را تغییر دهید.در حالت دوم و در سطح دیتابیس هم می توانید این کار را بکنید ولی در نظر داشته باشید که با وجود Collation در سطح دیتابیس می توانید Collation متفاوتی به جدول و حتی فیلد های جدول دهید.یعنی یک فیلد آن می تواند Collation از نوع Persion داشته باشد و فیلد دیگری می تواند Collation از نوع Arabic داشته باشد.
همراه با تعیین Collation برای جدول یا دیتابیس خود باید به چهار نکته توجه کنیم.
Case Sensitive :(به صورت مخفف CS). یعنی اینکه به حروف بزرگ و کوچک حساس باشد یا نه .مثلا در مود فارسی این گزینه نیازی نیست چون حروف فارسی بزرگ و کوچک ندارد
Accent Sensitive: (به صورت مخفف AS) این گزینه حساسیت نسبت به لهجه را ایجاد می کند
Conna Sensitive در برخی زبان ها مثلا زبان ژاپنی دو نوع فرمت نوشتن وجود دارد با این گزینه این حالت لحاظ خواهد شد.
Width Sensitive اگر فیلدهای ما Varchar باشن در یک بایت ذخیره خواهند شد.واگر Nvarchar باشند در دو بایت ذخیره خواهند شد
قبل از SQL 2008 ما می توانستیم از Collation به نام Arabic 1256 استفاده می کردیم منتها این Collation برای زبان ما مشکل ایجاد می کرد.این مشکل بین حروف ی و ک بود که حالت فارسی و عربی آن با هم متفاوت بود.در این حالت وقتی اطلاعات جدول را Order می کردیم نتیجه درستی به ما نمی داد چون حروف ی فارسی را یک جا می آورد و حروف ی عربی را هم یک جای دیگر.در ضمن اگر کاربری مثلا به دنبال علی باشد و علی در دیتابیس به صورت عربی ذخیره شده باشد در نتیجه جستجو نخواهد آمد.
ولی بعد از SQL 2008 یک نوع جدید Collation به دیتابیس اضافه شد به نام Persion که دیگر مشکل حروف ی و ک فارسی و عربی در آن حل شده است .
البته راه حل بهتری هم وجود دارد و آن این است که کاربر را ملزم به ورود ی و ک به صورت فقط فارسی کنیم.یا اینکه دیتای ورودی کاربر را به Collation فارسی تبدیل کرده و در دیتا بیس ذخیره کنیم .
در ایجا شاید جالب باشد تعریفی هم از Code Page ارائه دهیم . Code Page زبان مورد استفاده ماست .با انتخاب Code Page دیتابیس می فهمد از چه علائم و کاراکتر هایی استفاده کند. Code Page های مختلفی وجود داشتند ولی همگی تحت Unicode به صورت استاندارد در آمدند.Unicode برای هر علامت ، عدد ، کاراکتر یک کد خاص اختصاص داده است مستقل از زبان ، سیستم عامل و برنامه .
برای شرح بیشتر مفهوم Collation به جدول زیر توجه کنید. در فیلد Item_Name این فیلد هر دو خاصیت case sensitive و case insensitiveرا دارد.یعنی دیتاهای داخل آن به هر دو صورت بزرگ و کوچک ذخیره شده اند.
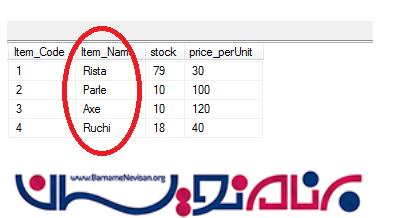
کوئری زیر را در دیتابیس اجرا می کنیم.
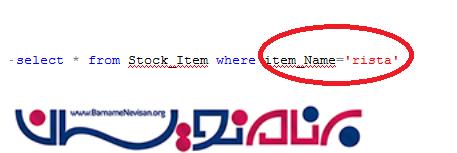
بعد از اجرا نتایج به صورتی است که هر دو حالت های بزرگ و کوچک آورده می شود .چرا؟ به خاطر اینکه خاصیت Collation نمونه یا Instance ما در هنگام نصب بر روی case insensitive است .به شکل زیر توجه کنید.
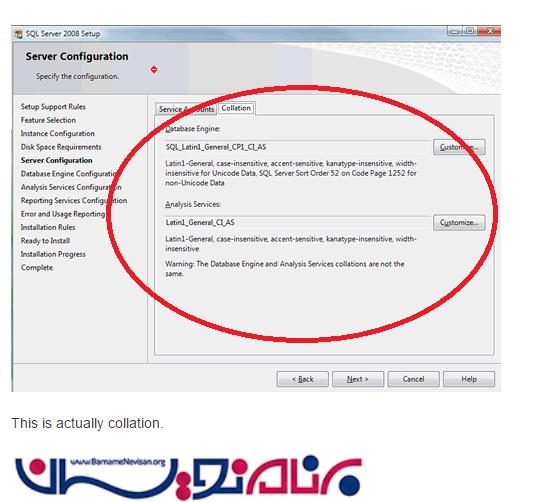
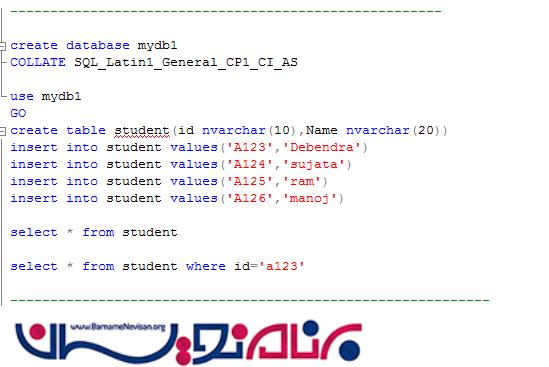
در کد زیر یک جدول با چندین مقدار ساخته شده است . Collation این دیتابیس بر روی case sensitive قرار داده شده است .
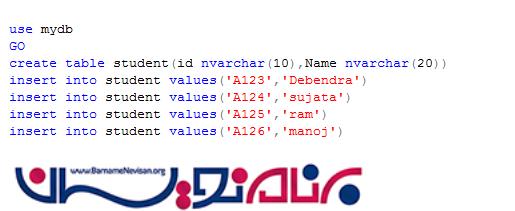
حال برای بازیابی رکوردی به صورت زیر عمل می کنیم.

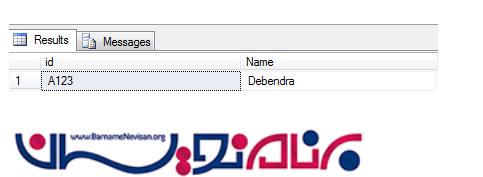
از آنجاییکه case sensitive هستیم نتیجه ای مطابق این کوئری یافت نخواهد شد.اما اگر یک دیتابیس دیگر به صورت زیر ایجاد کنیم وCollation آن را بر روی Case Insensitive(به صورت مخفف CI) قرار دهیم . کوئری بالا نتیجه خواهد داد.
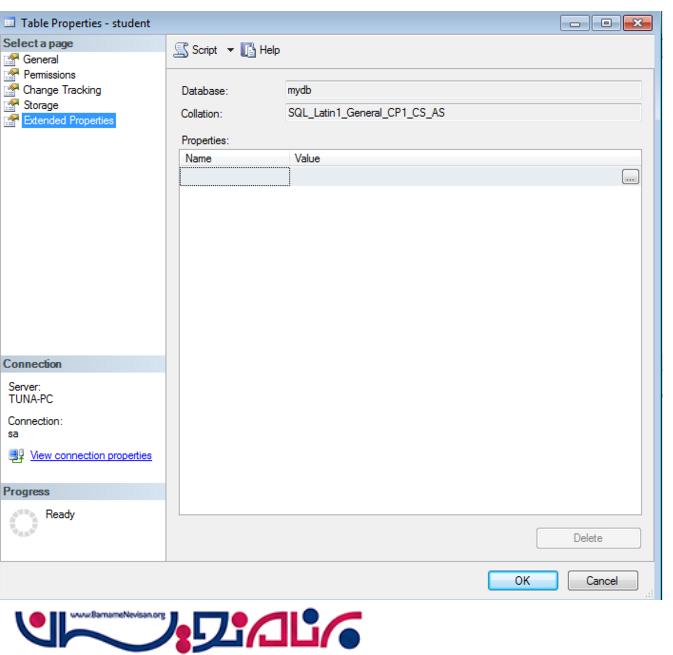
برای تغییر Collation بر روی جدول کلیک راست کنید.به گزینه Property بروید و سپس بر روی extended property کلیک کنید.به شکل زیر توجه کنید
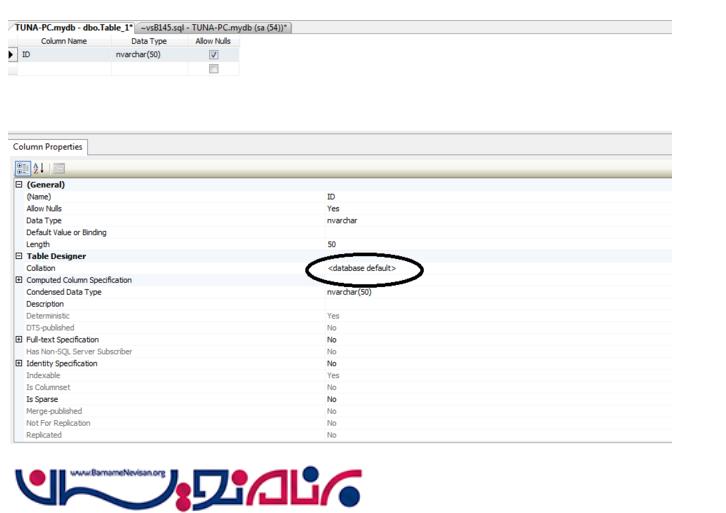
حال میتوانید با توجه به Code Page یعنی زبان مورد استفاده Collation مناسب را انتخاب کنید.اگر برای جداول خود به صورت جداگانه Collation انتخاب نکنید از Collation مربوط به Instance پیروی خواهند کرد.
در شکل زیر می بینید که جدول ما Collation خود را از دیتابیس می خواند.

- SQL Server
- 16k بازدید
- 5 تشکر